1 著者
Mu Li, Ziqi Liu, Alexander J. Smola, Yu-Xiang Wang
Computer Science, Carnegie Mellon University
WSDM 2016 のBest Paper Honorable Mentionに選ばれる
DMLC (xgboost, mxnet, minerva, parameter server...)
2 紹介者
バクフー株式会社 柏野雄太 @yutakashino
- Ovservational Cosmology
- Python / Zope
- Realtime Data Platform for Enterprise

3 ざっくり言うと
- DiFactoというFactorization Machineのメモリ効率を改善して分散学習をする仕組みを提案する
- LibFMなどの従来のFactorization Machineにくらべて高速に収束し,大きな問題に対処できる
4 背景と動機
- 推薦や予測(回帰・分類・ランキング)
- 線形モデルは大量のデータに対応できる
- 非線形モデルであるFactorization Machineは,特徴間の交互作用も入れることができて表現力が高い.しかし大量のデータを取り扱えない
- libFMなどの従来のFactrization Machineで扱える特徴量数は
109 くらいがせいぜい. - Creteo CTRデータセットのような現実的なデータは,
1011 くらいの特徴数になったり,100次のEmbedding Matrixを考えなければいけない.その場合,Factrization Machineはつかえない.
- libFMなどの従来のFactrization Machineで扱える特徴量数は
- Factorization Modelで線型モデルのような大量のデータを扱うにはどうするか
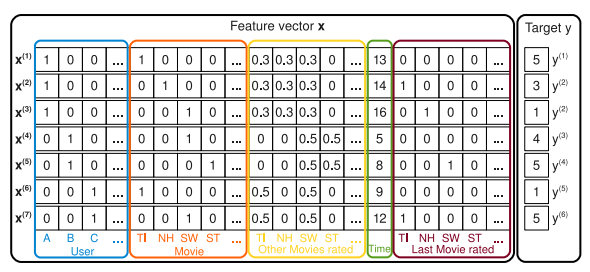
5 Factorization Machine
- Factorization Machineの特徴ベクトル:トランザクションを並べて特徴を全部一緒くたにする
- 線型モデルに embbeding Matrix
V の項を拡張する - 線型モデルの重み
w とembbeding MatrixV をSGD等により推定
5.1 線型モデルとの関係
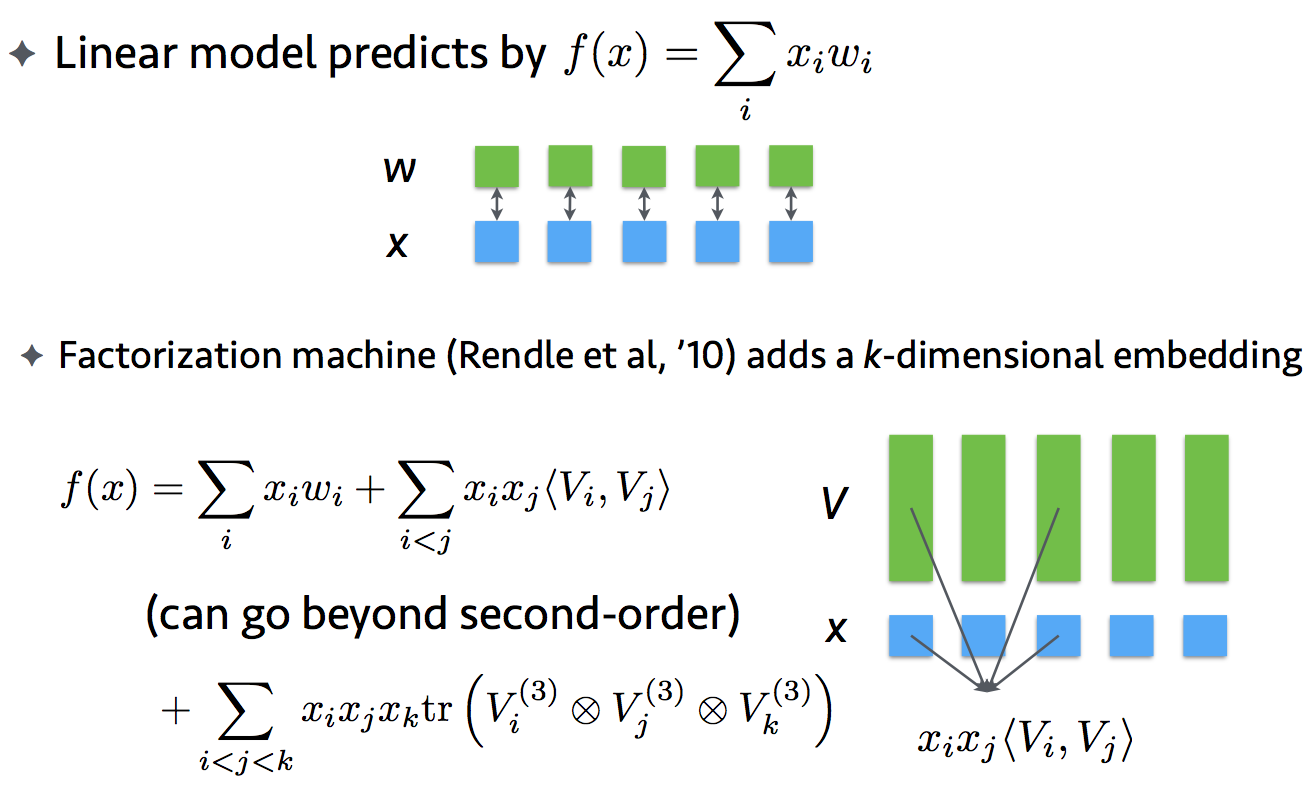
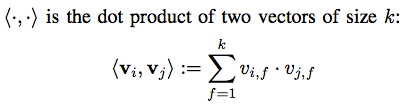
5.2 実装
- libFM (C) 本家 https://github.com/srendle/libfm
- fastFM (C + Cython) 多機能+速い https://github.com/ibayer/fastFM
- pyFM (Python/Numpy) 実装が簡単 https://github.com/coreylynch/pyFM
./libFM -task r -train ml1m-train.libfm -test ml1m-test.libfm -dim ’1,1,8’
6 DiFactoモデル
6.1 キャッチ
従来のFactrization Machineを改善
- Memory Adaptive Constraints:embedding matrix Vのメモリを圧縮
- Sparse Regularization: 効かないwを0にする
- Frequency Adaptive Regularization: 高次の正則化
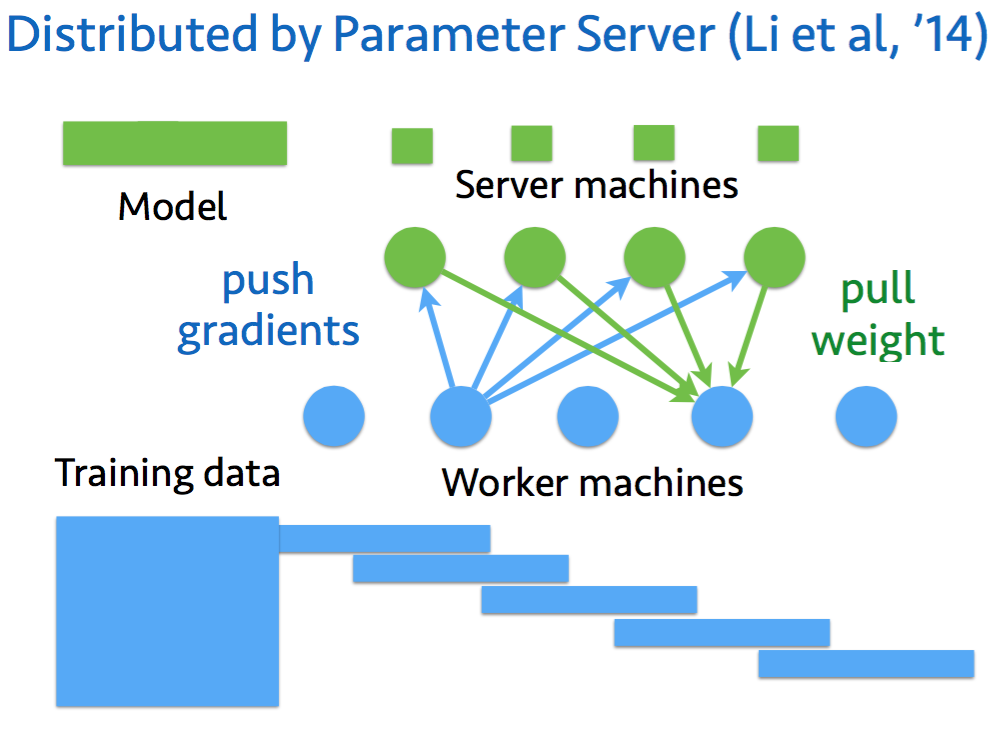
- 分散学習: Parameter Serverの仕組みで,重みV, wのアップデートをサーバで,勾配計算をワーカーに分散化
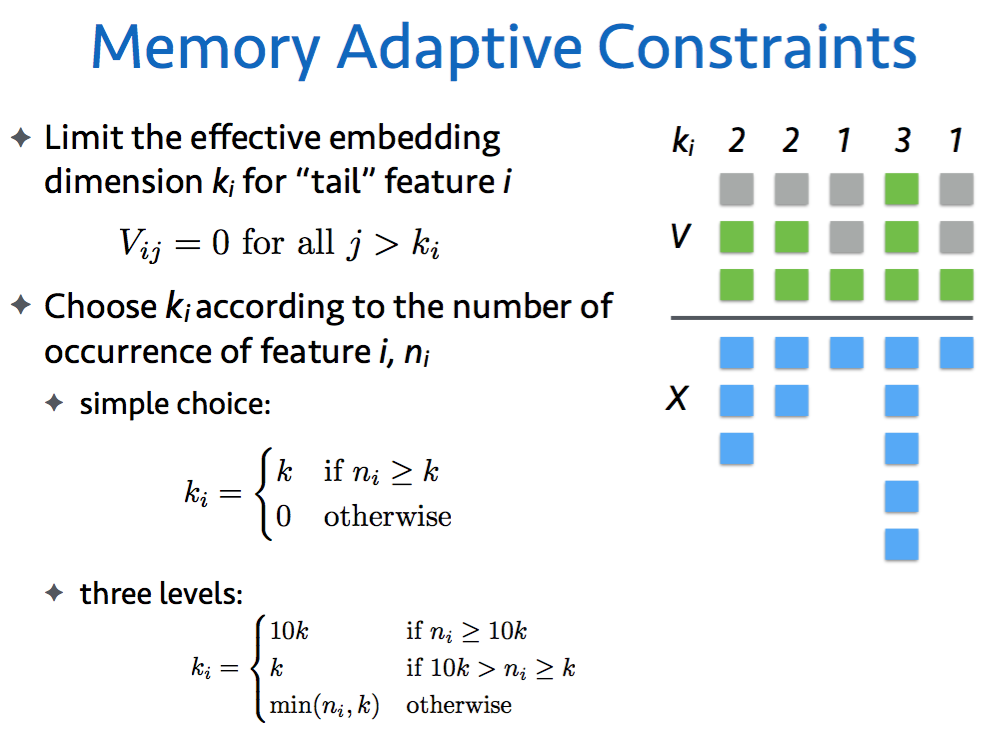
6.2 Memory Adaptive Constraints
Frequency threshold
6.3 Sparse Regularization

6.4 Frequency Adaptive Regularization
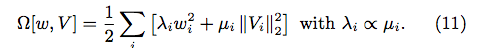
6.5 結局最適化は…
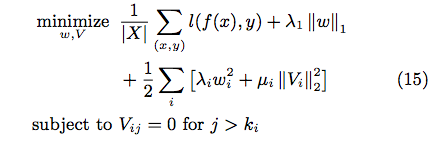
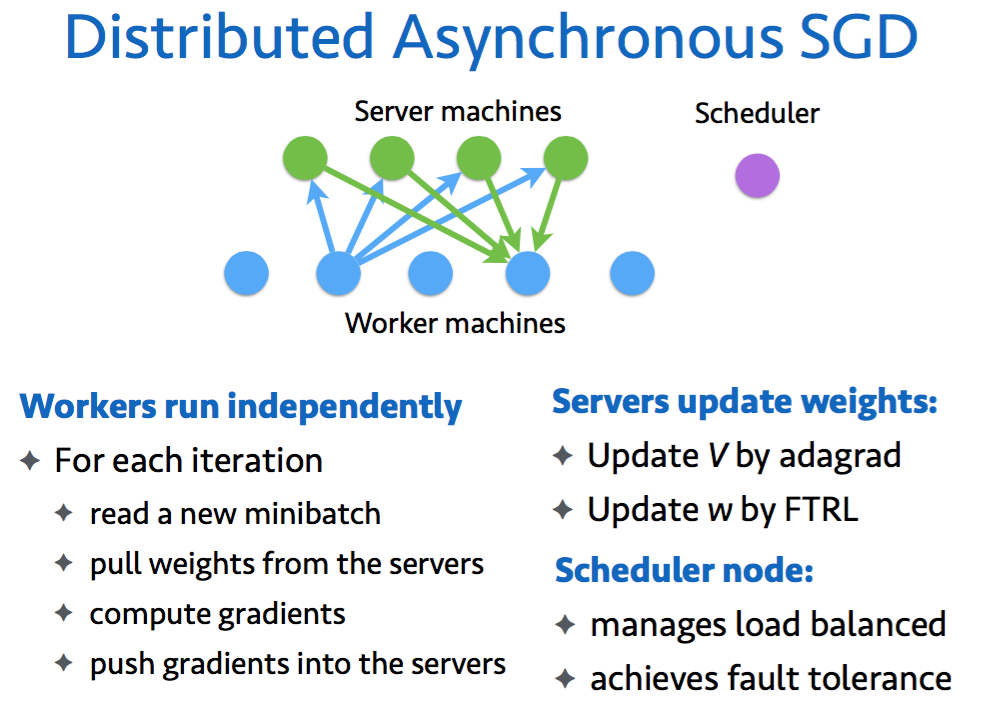
7 分散学習
Parameter Serverの仕組みで,重みV, wのアップデートをサーバで,勾配計算をワーカーに分散化
7.1 gradient
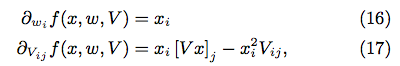
7.2 update V
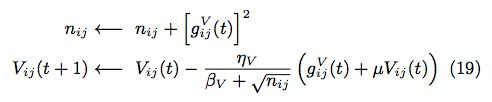
7.3 update w
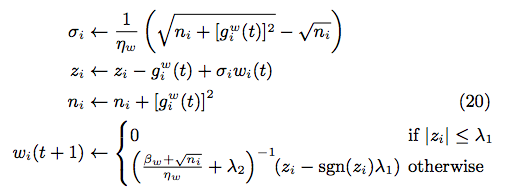
7.4 収束解析
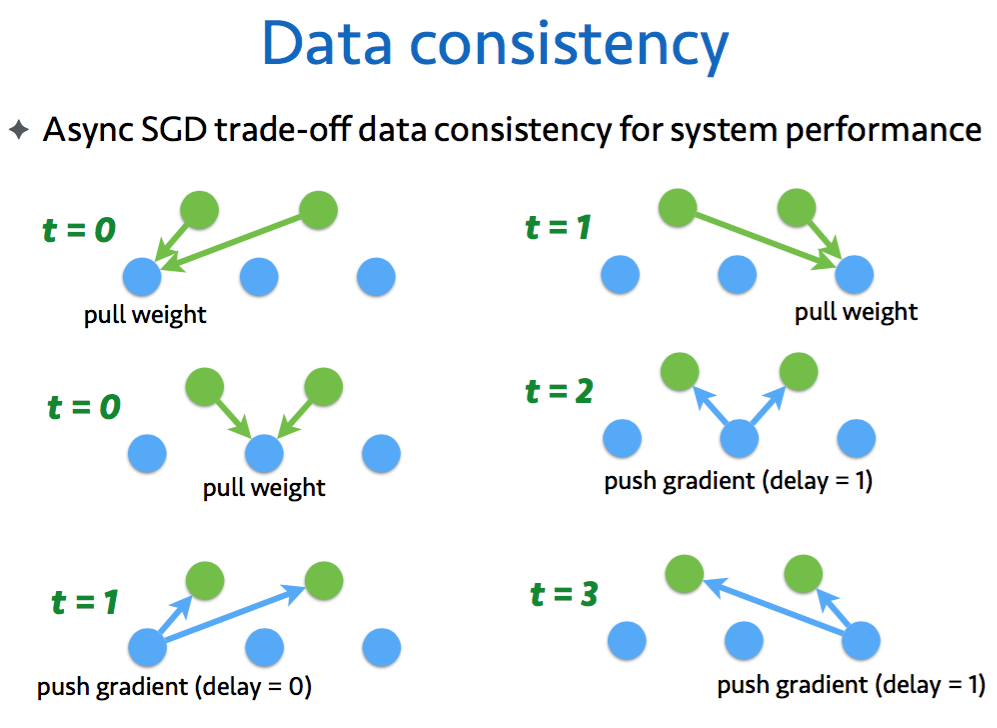

7.5 分散学習の実装
#Start: Create one scheduler node, m worker nodes and nserver nodes over multiple machines.
#Scheduler Node:
Assume the data is partitioned into s parts p1, . . . , ps,
for t = 1 to T do
Work packages P = {p1, . . . , ps}
Accomplished packages A = ∅
while P 6= ∅ do
switch detected event from worker i do
case idle
Pick p ∈ P \ A and assign p to worker i
A = A ∪ {p},
case finished p
P = P \ {p}
case dead or timeout
A = A \ {p},
end while
end for
#Worker i:
Receive command “processing p” from the scheduler
while read a minibatch from p do
Pull wi and Vi from server nodes for all features ithat appear in this minibatch
Compute the gradient based on (16) and (17)
Push gradient back to servers
end while
#Server i:
if received gradient from a worker then
update w and V by using (20) and (19)
end if
8 DiFactoの実際の使い方
build/difacto data_in=data/gisette_scale val_data=data/gisette_scale.t lr=.02 V_dim=2 V_lr=.001
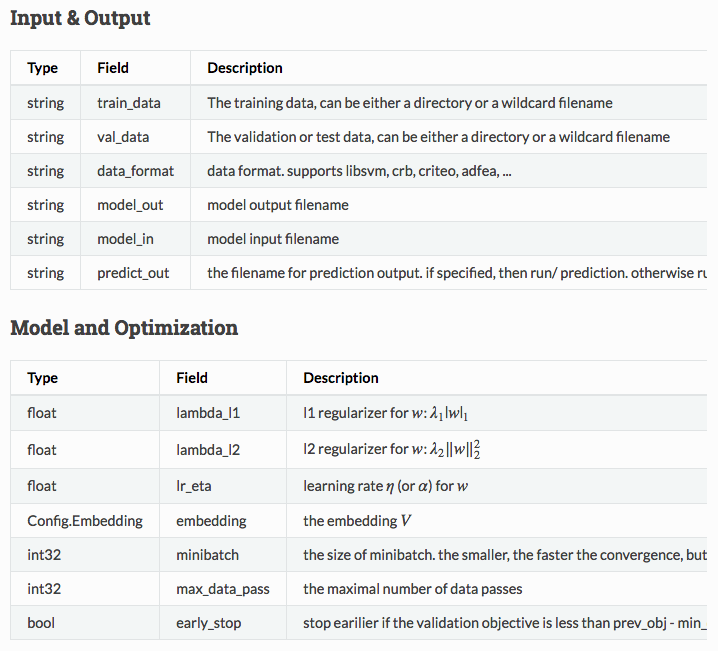
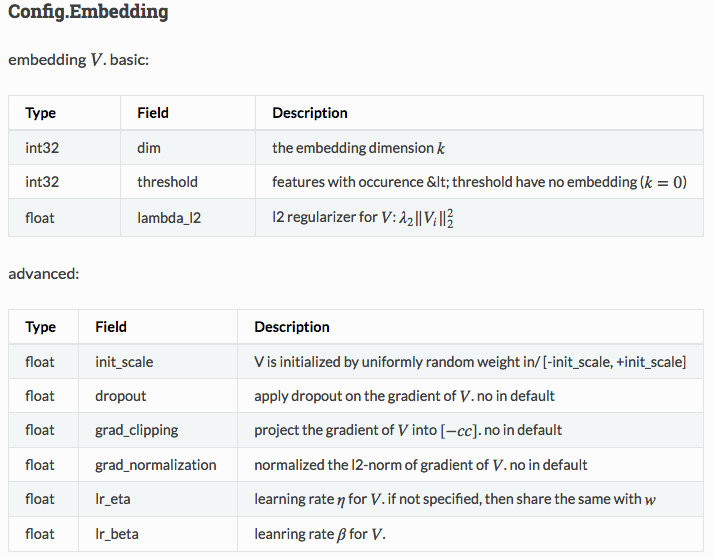
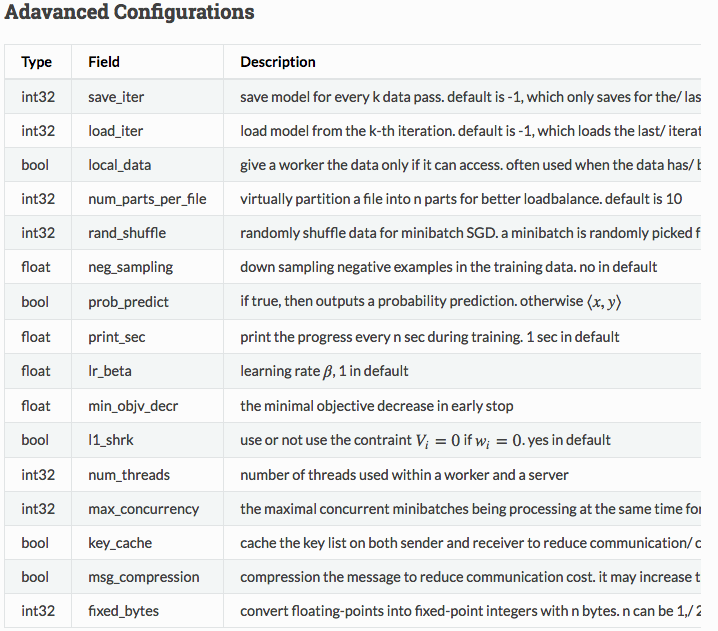
tracker/dmlc_local.py -n 2 -s 1 bin/difacto.dmlc learn/difacto/guide/train.conf
train.conf
train_data = "data/train-part_[0-1].*"
val_data = "data/train-part_2.*"
data_format = "libsvm"
model_out = "model/criteo"
embedding {
dim = 16
threshold = 16
lambda_l2 = 0.0001
}
lambda_l1 = 4
lr_eta = .01
max_data_pass = 1
minibatch = 1000
early_stop = 1
EOF
9 実験結果
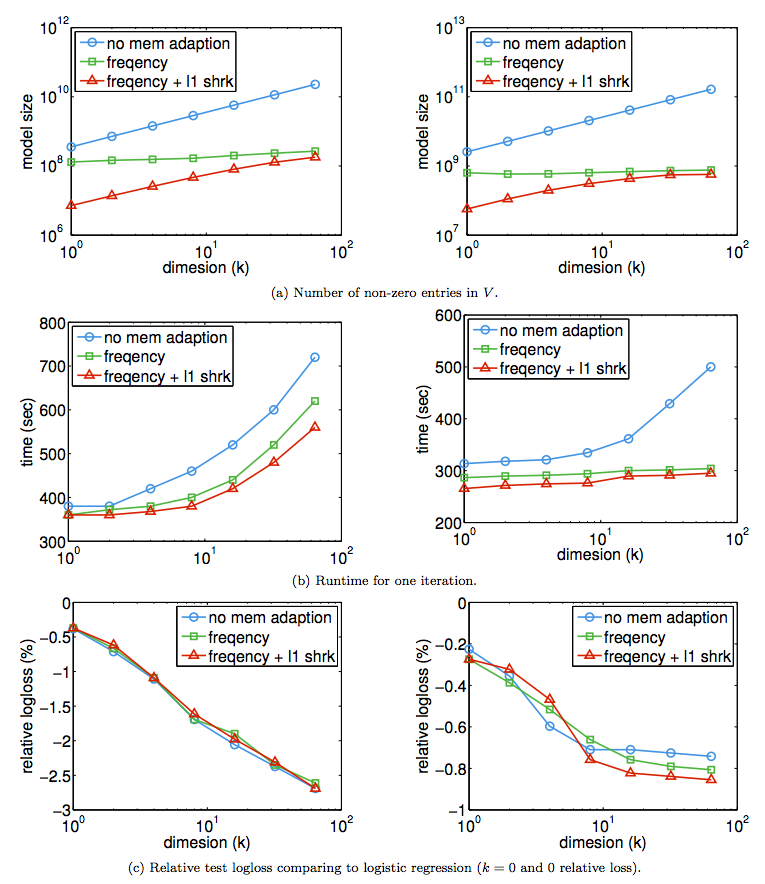
9.1 Adaptive Memory
- Criteo2, CTR2の次元
k を大きくしたときの,サイズ,収束時間,正確性 - no mem adaption vs. freq threshold vs. freq threshold +
l1 shrinkage - メモリの効果大
k=64 で300倍効く - イテレーションあたりの経過時間:
k がデカイと短くなる.(CTR2で20%改善) - 正確性:Criteo2はほとんど変わらない.CTR2では若干改善
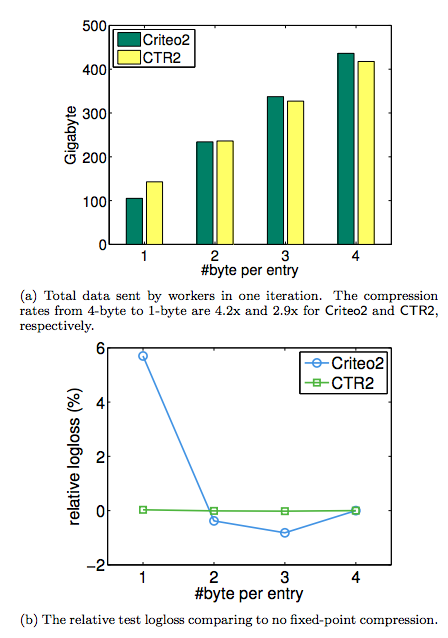
9.2 Fixed-point Compression
デフォルトで浮動小数点32 bitで表現されるgradientやモデルパラメータを精度の低い整数に「圧縮」して,ネットワーク負荷を下げたときに,どうなるか.
(a) 圧縮度が高いとネットワーク負荷は下がる(当たり前)
(b) 正確度について,CTR2は変わらない.Criteo2は一番圧縮度の高いときに6%ほど正確度が下がるのは当然だけれど,圧縮度が低いからといって,正確性が高くなるわけではないことがわかった.
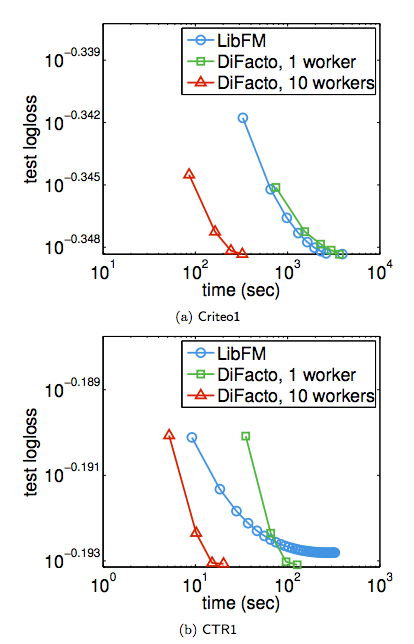
9.3 LibFMとの比較
- Creteo1, CTR1の収束速度
- LibFMはデカイデータセットCreteo2, CTR2を実行できなかった
- LibFM vs. DiFacto 1 vs. DiFacto 10
- LibFM vs. Difacto * 1ではLibFMのほうが良い場合もあるが,ワーカーを増やすとDiFactoの圧勝
10 結論
Factorization MachineにAdaptive MemoryとFrequency adaptive正則化を入れ,Parameter Serverの仕組みで分散化させたDiFactoは,大きな問題を高速に取り扱うことができる.